Lecture 17: Introduction to PySpark & Resilient Distributed Datasets (RDD)#
Part A - Learning Objectives#
By the end of this lecture, students should be able to:
Understand what is Spark and its main components
How Spark is different from Hadoop’s Map Reduce
What are the key use case of Spark
Set up a databricks workspace
Apache Spark - An unified engine for large-scale analysis#
Apache Spark is an unified analytics engine designed for large-scale data processing. It offers high-level APIs in Java, Scala, Python, and R, along with an optimized engine that supports general execution graphs. Additionally, Spark includes a robust suite of higher-level tools such as Spark SQL for SQL and structured data processing, pandas API on Spark for handling pandas workloads, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.

Key benefits of Spark:#
Speed
Engineered from the bottom-up for performance, Spark can be 100x faster than Hadoop for large scale data processing by exploiting in memory computing and other optimizations. Spark is also fast when data is stored on disk, and currently holds the world record for large-scale on-disk sorting.
Ease of Use
Spark has easy-to-use APIs for operating on large datasets. This includes a collection of over 100 operators for transforming data and familiar data frame APIs for manipulating semi-structured data.
A Unified Engine
Spark comes packaged with higher-level libraries, including support for SQL queries, streaming data, machine learning and graph processing. These standard libraries increase developer productivity and can be seamlessly combined to create complex workflows.

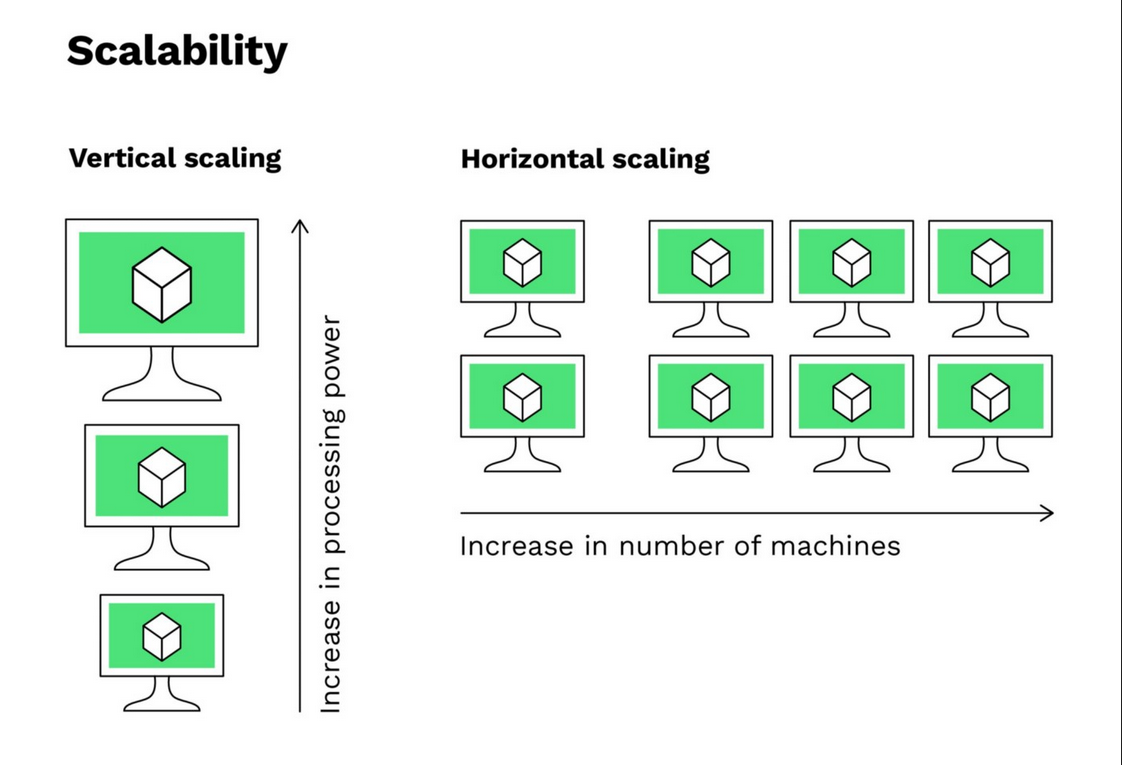
The big idea behind distributed computing#
Distributed computing is a model in which components of a software system are shared among multiple computers to improve efficiency and performance. To understand this concept, let’s use the analogy of searching through a yellow phone book.
The Yellow Phone Book Analogy#
Imagine you have a massive yellow phone book with millions of entries, and you need to find the phone number of a specific person. Doing this task alone would be time-consuming and tedious. Now, let’s break down how distributed computing can make this process faster and more efficient.

Single Worker (Non-Distributed Computing)#
Scenario: One person (a single computer) is tasked with finding the phone number.
Process: The person starts from the first page and goes through each entry sequentially until they find the desired phone number.
Time: This process can take a long time, especially if the phone book is enormous.
Vertical scaling: Enhancing the capabilities of a single computer by adding more CPU, memory, or faster storage.
Multiple Workers (Distributed Computing)#
Scenario: You have a team of people (multiple computers) to help you search through the phone book.
Process:
Divide the Task: Split the phone book into equal sections and assign each section to a different person.
Parallel Search: Each person searches their assigned section simultaneously.
Combine Results: Once a person finds the phone number, they inform the rest of the team, and the search stops.
Time: The search process is significantly faster because multiple sections are being searched at the same time.
Horizontal scaling: Adding more computers to the system to share the workload.
Key Concepts in Distributed Computing#
Parallelism: Just like multiple people searching different sections of the phone book simultaneously, distributed computing involves multiple processors working on different parts of a task at the same time.
Scalability: Adding more workers (computers) can further speed up the search process. Similarly, distributed systems can scale by adding more nodes to handle larger workloads.
Fault Tolerance: If one person gets tired or makes a mistake, others can continue the search. In distributed computing, if one node fails, other nodes can take over its tasks, ensuring the system remains operational.
Coordination: Effective communication and coordination are essential. In our analogy, workers need to inform each other when the phone number is found. In distributed systems, nodes must coordinate to share data and results.
Spark and Hadoop’s ecosystem#
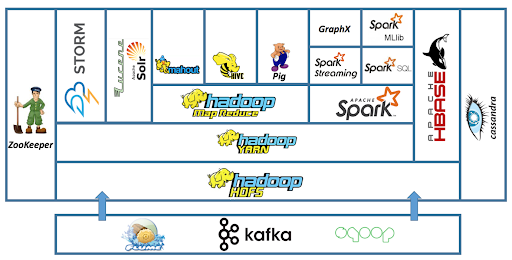
Credit: https://tutorials.freshersnow.com/hadoop-tutorial/hadoop-ecosystem-components/
Hadoop Ecosystem#
Hadoop Distributed File System (HDFS): is a special file system that stores large datasets across multiple computers. These computers are called Hadoop clusters.
MapReduce: allows programs to break large data processing tasks into smaller ones and runs them in parallel on multiple servers.
YARN (Yet Another Resource Negotiator): schedules tasks and allocates resources to applications running on Hadoop.
Spark Ecosystem#
Spark Core: The foundation of the Spark framework, responsible for basic I/O functionalities, task scheduling, and memory management.
Spark SQL: Allows querying of structured data via SQL and supports integration with various data sources.
Spark Streaming: Enables real-time data processing and analytics.
MLlib: A library for scalable machine learning algorithms.
GraphX: A library for graph processing and analysis.
SparkR: An R package that provides a lightweight frontend to use Apache Spark from R.
Key Differences: Hadoop vs. Spark#
Hadoop |
Spark |
|
|---|---|---|
Architecture |
Hadoop stores and processes data on external storage. |
Spark stores and process data on internal memory. |
Performance |
Hadoop processes data in batches. |
Spark processes data in real time. |
Cost |
Hadoop is affordable. |
Spark is comparatively more expensive. |
Scalability |
Hadoop is easily scalable by adding more nodes. |
Spark is comparatively more challenging. |
Machine learning |
Hadoop integrates with external libraries to provide machine learning capabilities. |
Spark has built-in machine learning libraries. |
Security |
Hadoop has strong security features, storage encryption, and access control. |
Spark has basic security. IT relies on you setting up a secure operating environment for the Spark deployment. |
Hadoop use cases#
Hadoop is most effective for scenarios that involve the following:
Processing big data sets in environments where data size exceeds available memory
Batch processing with tasks that exploit disk read and write operations
Building data analysis infrastructure with a limited budget
Completing jobs that are not time-sensitive
Historical and archive data analysis
Spark use cases#
Spark is most effective for scenarios that involve the following:
Dealing with chains of parallel operations by using iterative algorithms
Achieving quick results with in-memory computations
Analyzing stream data analysis in real time
Graph-parallel processing to model data
All ML applications
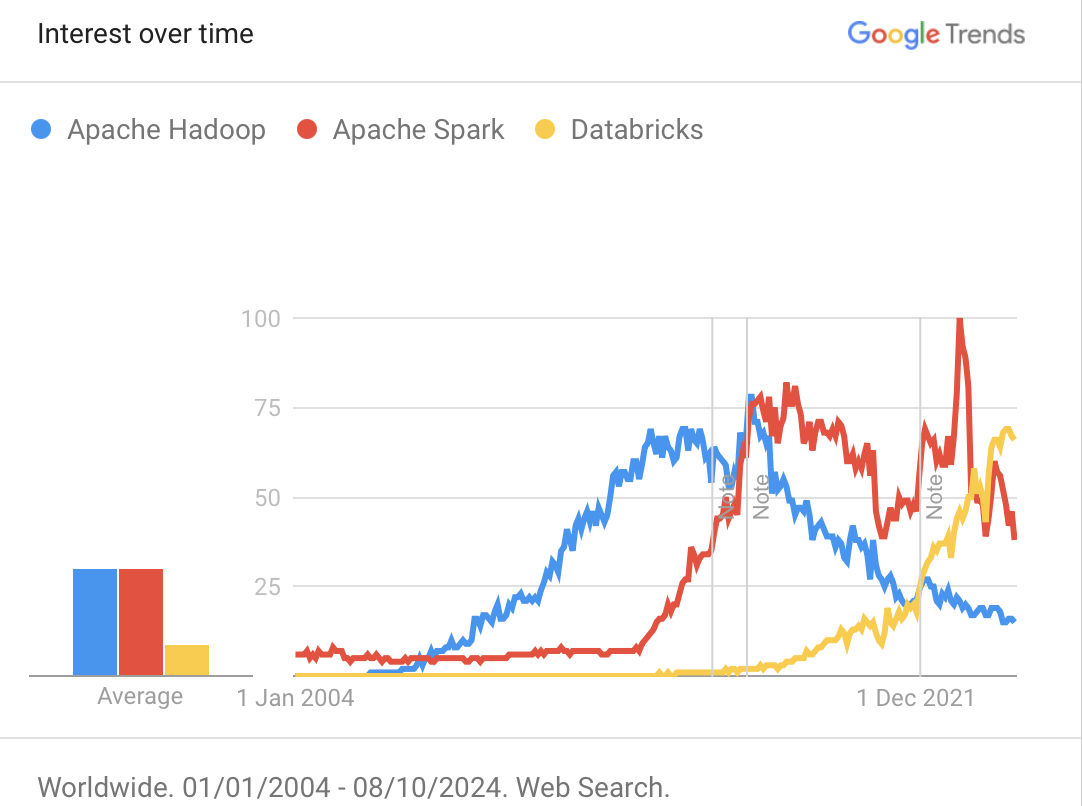
Spark and Databricks#
Introduction to Databricks#
Databricks: A cloud-based platform designed to simplify big data processing and analytics. It was founded by the creators of Apache Spark and provides a unified environment for data engineering, data science, and machine learning.
Key Features of Databricks#
Managed Spark Environment: Databricks offers a fully managed Spark environment, which simplifies the deployment, management, and scaling of Spark applications.
Collaborative Workspace: Provides a collaborative workspace where data engineers, data scientists, and analysts can work together on data projects.
Optimized Spark Engine: Includes performance optimizations over open-source Spark, making it faster and more efficient.
Integrated Machine Learning: Simplifies the process of building, training, and deploying machine learning models.
Interactive Notebooks: Supports interactive notebooks that allow users to write code, visualize data, and share insights in a single document.
Relation to Apache Spark#
Founders: Databricks was founded by the original creators of Apache Spark, ensuring deep integration and optimization for Spark workloads.
Enhanced Spark Capabilities: Databricks enhances Spark’s capabilities by providing additional features such as optimized performance, collaborative tools, and integrated machine learning.
Unified Analytics Platform: Combines the power of Spark with additional tools and services to create a comprehensive platform for big data analytics and machine learning.
Benefits of Using Databricks with Spark#
Ease of Use: Simplifies the setup and management of Spark clusters, allowing users to focus on data processing and analysis.
Scalability: Automatically scales resources based on workload demands, ensuring efficient use of resources.
Performance: Provides performance improvements over open-source Spark, making data processing faster and more efficient.
Collaboration: Facilitates collaboration among team members through shared notebooks and integrated workflows.
Security: Offers robust security features, including data encryption, access controls, and compliance with industry standards.
Sign up for Databricks Community edition#
Click Try Databricks here
Enter your name, company, email, and title, and click Continue.
On the Choose a cloud provider dialog, click the Get started with Community Edition link. You’ll see a page announcing that an email has been sent to the address you provided.
Look for the welcome email and click the link to verify your email address. You are prompted to create your Databricks password.
When you click Submit, you’ll be taken to the Databricks Community Edition home page
Getting started with PySpark (locally)#
Environment set up#
conda install conda-forge::openjdk
pip install pyspark
Spark session
A Spark session is the entry point to programming with Spark. It allows you to create DataFrames, register DataFrames as tables, execute SQL queries, and read data from various sources
You initialize a Spark session using SparkSession.builder. The appName method sets the name of your application, which can be useful for debugging and monitoring.
# run this if you are on Windows machine
# this will set the environment variables for PySpark to use the correct Python executable
import os
import sys
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executable
from pyspark.sql import SparkSession
# Initialize Spark Session
spark = SparkSession.builder \
.master("local[1]") \
.appName("DataFrame Example") \
.getOrCreate()
spark
24/11/12 08:38:44 WARN Utils: Your hostname, Quans-MacBook-Pro.local resolves to a loopback address: 127.0.0.1; using 192.168.1.225 instead (on interface en0)
24/11/12 08:38:44 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
24/11/12 08:38:44 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
SparkSession - in-memory
24/11/12 08:38:59 WARN GarbageCollectionMetrics: To enable non-built-in garbage collector(s) List(G1 Concurrent GC), users should configure it(them) to spark.eventLog.gcMetrics.youngGenerationGarbageCollectors or spark.eventLog.gcMetrics.oldGenerationGarbageCollectors
Explanation:#
SparkSession.builder: Entry point to create a SparkSession.
master(“local[1]”): Run Spark locally with one thread.
appName(“DataFrame Example”): Set the name of the Spark application.
getOrCreate(): Retrieve an existing SparkSession or create a new one if it does not exist.
# Create a DataFrame from a list of tuples
data = [(1, "Alice"), (2, "Bob"), (3, "Cathy")]
columns = ["id", "name"]
df = spark.createDataFrame(data, columns)
df
DataFrame[id: bigint, name: string]
# show data using pyspark show() function
df.show()
+---+-----+
| id| name|
+---+-----+
| 1|Alice|
| 2| Bob|
| 3|Cathy|
+---+-----+
Part B - Learning Objectives#
By the end of this lecture, students should be able to:
Understand the concept of Resilient Distributed Datasets (RDDs) in Apache Spark.
Explain the immutability and fault tolerance features of RDDs.
Describe how RDDs enable parallel processing in a distributed computing environment.
Identify the key features of RDDs, including lazy evaluation and partitioning.
Introduction to RDDs#
Resilient Distributed Datasets (RDDs) are a foundational component in Apache Spark. They represent a distributed collection of data, partitioned across a cluster, which allows for parallel processing. RDDs are the core abstraction that enables Spark to handle large datasets efficiently across multiple machines.
Immutability: Once created, RDDs cannot be modified. Instead of changing an existing RDD, transformations (like map, filter, etc.) generate a new RDD from the original one. This immutability helps ensure consistency across distributed systems, as different machines or processes are always working with the same, unchangeable data.
Parallel processing: Since RDDs are distributed across multiple nodes, operations on them can be performed in parallel, leveraging the full power of a distributed computing environment. This makes it possible to process vast amounts of data much faster than on a single machine.
Fault tolerance: One of the key features of RDDs is their ability to recover from failures without the need to replicate the entire dataset. This is achieved through lineage, a concept where RDDs keep track of how they were derived from other RDDs. If a node or partition fails, Spark can use this lineage information to recompute only the affected parts of the dataset, minimizing data loss and avoiding the overhead of redundant copies.
Key Features of RDDs#
1. Immutability#
Once created, RDDs cannot be changed. Transformations on RDDs produce new RDDs.
What is immutable object?
In Python, immutability refers to objects whose state cannot be modified after they are created. For example, string, number, tuples are immutable objects in Python.
For example, when you try to overwrite the first letter of a string, it will give an error
string1 = 'Hello world'
string1[0] = 'A'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
File <command-1503943367388992>, line 2
1 string1 = 'Hello world'
----> 2 string1[0] = 'A'
TypeError: 'str' object does not support item assignment
Same for tuple. You cannot overwrite the object
tuple1 = (1, 2, 3)
tuple1[0] = 4
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
File <command-1503943367389002>, line 2
1 tuple1 = (1, 2, 3)
----> 2 tuple1[0] = 4
TypeError: 'tuple' object does not support item assignment
But with list you can, because list is mutable
list1 = [1, 2, 3]
list1[0] = 4
list1
[4, 2, 3]
Now come back to RDDs, what immutability means here is the fact that any transformation done on the data will create a new copy of the data, instead of overwriting it. This ensures that the original dataset remains unchanged, allowing for safer parallel processing and easier debugging.
2. Lazy Evaluation#
Transformations on RDDs are not executed immediately. They are computed only when an action is called. This means that Spark builds up a plan of transformations to apply when an action is finally invoked, optimizing the execution process and reducing unnecessary computations.
For example let’s take the following dataframe.
from pyspark.sql import SparkSession
# Initialize Spark Session
spark = SparkSession.builder.appName("DataFrame Example").getOrCreate()
spark
# Create a Spark DataFrame
data = [(1, 'Alice'), (2, 'Bob'), (3, 'Cathy')]
columns = ['id', 'name']
df = spark.createDataFrame(data, columns)
display(df)
| id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Cathy |
We want to filter the dataset based on id column. When you run the code cell below, actually nothing happen. PySpark will record the transformation but do not execute it yet. Think of it as PySpark writes down a recipe, but no food has been cooked yet
# Define a transformation (lazy evaluation)
filtered_df = df.filter(df['id'] > 1)
It will only execute the transformations when we trigger an action, such as show
# Action to trigger the evaluation
filtered_df.show()
| id | name |
|---|---|
| 2 | Bob |
| 3 | Cathy |
3. Fault Tolerance#
RDDs track lineage information to rebuild lost data. For example, if a partition of an RDD is lost due to a node failure, the RDD can use its lineage information to recompute the lost partition from the original data source or from other RDDs.
4. Partitioning#
RDDs are divided into partitions, which can be processed in parallel across the cluster.
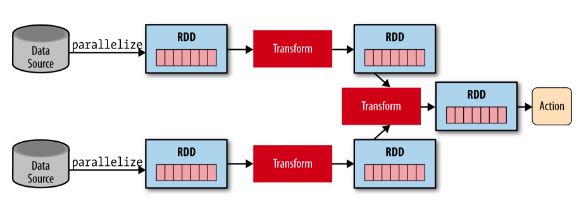
Transformations & Actions#
As we discussed above, RDDs is lazy-evaluated, which means it won’t execute the transformations until an action is triggered. Let’s have a closer look at this using some examples
Example: Creating RDDs from a csv File#
First, let’s try to read in a data file from an URL
# Import CSV from the given URL
url = "https://github.com/selva86/datasets/raw/master/AirPassengers.csv"
from pyspark import SparkFiles
# Add the file to the SparkContext
spark.sparkContext.addFile(url)
# Read the file
rdd = spark.sparkContext.textFile("file://"+SparkFiles.get("AirPassengers.csv"))
# Extract header
header = rdd.first()
# Remove header and split by commas
rdd = rdd.filter(lambda row: row != header).map(lambda row: row.split(","))
Can you guess where the data are being stored? They were actually partitioned and stored acrossed multiple servers. This is distributed computing! To see the number of partitions, we can run
rdd.getNumPartitions()
2
Let’s see what happens when we just try to display the dataframe by typing df. Typically, if this was a pandas.DataFrame, it woul display the first few rows.
However, since Spark is lazy-evaluated, it doesn’t display the data yet
rdd
PythonRDD[58] at RDD at PythonRDD.scala:61
To display the data, you need to trigger an action.
Now let’s trigger an action called collect(). The collect() function in PySpark is used to retrieve the entire dataset from the distributed environment (i.e., the cluster) back to the driver program as a list.
This method is often used for debugging or small datasets because it brings all the data into the driver’s memory, which can lead to memory issues if the dataset is large.
rdd.collect()
[['1949-01-01', '112'],
['1949-02-01', '118'],
['1949-03-01', '132'],
['1949-04-01', '129'],
['1949-05-01', '121'],
['1949-06-01', '135'],
['1949-07-01', '148'],
['1949-08-01', '148'],
['1949-09-01', '136'],
['1949-10-01', '119'],
['1949-11-01', '104'],
['1949-12-01', '118'],
['1950-01-01', '115'],
['1950-02-01', '126'],
['1950-03-01', '141'],
['1950-04-01', '135'],
['1950-05-01', '125'],
['1950-06-01', '149'],
['1950-07-01', '170'],
['1950-08-01', '170'],
['1950-09-01', '158'],
['1950-10-01', '133'],
['1950-11-01', '114'],
['1950-12-01', '140'],
['1951-01-01', '145'],
['1951-02-01', '150'],
['1951-03-01', '178'],
['1951-04-01', '163'],
['1951-05-01', '172'],
['1951-06-01', '178'],
['1951-07-01', '199'],
['1951-08-01', '199'],
['1951-09-01', '184'],
['1951-10-01', '162'],
['1951-11-01', '146'],
['1951-12-01', '166'],
['1952-01-01', '171'],
['1952-02-01', '180'],
['1952-03-01', '193'],
['1952-04-01', '181'],
['1952-05-01', '183'],
['1952-06-01', '218'],
['1952-07-01', '230'],
['1952-08-01', '242'],
['1952-09-01', '209'],
['1952-10-01', '191'],
['1952-11-01', '172'],
['1952-12-01', '194'],
['1953-01-01', '196'],
['1953-02-01', '196'],
['1953-03-01', '236'],
['1953-04-01', '235'],
['1953-05-01', '229'],
['1953-06-01', '243'],
['1953-07-01', '264'],
['1953-08-01', '272'],
['1953-09-01', '237'],
['1953-10-01', '211'],
['1953-11-01', '180'],
['1953-12-01', '201'],
['1954-01-01', '204'],
['1954-02-01', '188'],
['1954-03-01', '235'],
['1954-04-01', '227'],
['1954-05-01', '234'],
['1954-06-01', '264'],
['1954-07-01', '302'],
['1954-08-01', '293'],
['1954-09-01', '259'],
['1954-10-01', '229'],
['1954-11-01', '203'],
['1954-12-01', '229'],
['1955-01-01', '242'],
['1955-02-01', '233'],
['1955-03-01', '267'],
['1955-04-01', '269'],
['1955-05-01', '270'],
['1955-06-01', '315'],
['1955-07-01', '364'],
['1955-08-01', '347'],
['1955-09-01', '312'],
['1955-10-01', '274'],
['1955-11-01', '237'],
['1955-12-01', '278'],
['1956-01-01', '284'],
['1956-02-01', '277'],
['1956-03-01', '317'],
['1956-04-01', '313'],
['1956-05-01', '318'],
['1956-06-01', '374'],
['1956-07-01', '413'],
['1956-08-01', '405'],
['1956-09-01', '355'],
['1956-10-01', '306'],
['1956-11-01', '271'],
['1956-12-01', '306'],
['1957-01-01', '315'],
['1957-02-01', '301'],
['1957-03-01', '356'],
['1957-04-01', '348'],
['1957-05-01', '355'],
['1957-06-01', '422'],
['1957-07-01', '465'],
['1957-08-01', '467'],
['1957-09-01', '404'],
['1957-10-01', '347'],
['1957-11-01', '305'],
['1957-12-01', '336'],
['1958-01-01', '340'],
['1958-02-01', '318'],
['1958-03-01', '362'],
['1958-04-01', '348'],
['1958-05-01', '363'],
['1958-06-01', '435'],
['1958-07-01', '491'],
['1958-08-01', '505'],
['1958-09-01', '404'],
['1958-10-01', '359'],
['1958-11-01', '310'],
['1958-12-01', '337'],
['1959-01-01', '360'],
['1959-02-01', '342'],
['1959-03-01', '406'],
['1959-04-01', '396'],
['1959-05-01', '420'],
['1959-06-01', '472'],
['1959-07-01', '548'],
['1959-08-01', '559'],
['1959-09-01', '463'],
['1959-10-01', '407'],
['1959-11-01', '362'],
['1959-12-01', '405'],
['1960-01-01', '417'],
['1960-02-01', '391'],
['1960-03-01', '419'],
['1960-04-01', '461'],
['1960-05-01', '472'],
['1960-06-01', '535'],
['1960-07-01', '622'],
['1960-08-01', '606'],
['1960-09-01', '508'],
['1960-10-01', '461'],
['1960-11-01', '390'],
['1960-12-01', '432']]
The take() function in PySpark is used to retrieve a specified number of elements from an RDD or DataFrame. It returns the first n elements as a list, where n is the number you specify.
rdd.take(10)
[['1949-01-01', '112'],
['1949-02-01', '118'],
['1949-03-01', '132'],
['1949-04-01', '129'],
['1949-05-01', '121'],
['1949-06-01', '135'],
['1949-07-01', '148'],
['1949-08-01', '148'],
['1949-09-01', '136'],
['1949-10-01', '119']]
RDD Transformations#
Transformations are operations on RDDs that return a new RDD.
Examples include
map(),filter(),flatMap(),reduceByKey(), andjoin().
Example: Using map() and filter()#
# Create an RDD from a list
rdd = sc.parallelize(range(1, 101))
# Use map to square each element
squared_rdd = rdd.map(lambda x: x ** 2)
# Apply a filter transformation to keep only even numbers
even_rdd = squared_rdd.filter(lambda x: x % 2 == 0)
squared_rdd
PythonRDD[67] at RDD at PythonRDD.scala:61
Notice that when we try to print out squared_rdd, nothing happens, because we have not trigger an action
# Collect and print the results
print(even_rdd.collect())
[4, 16, 36, 64, 100, 144, 196, 256, 324, 400, 484, 576, 676, 784, 900, 1024, 1156, 1296, 1444, 1600, 1764, 1936, 2116, 2304, 2500, 2704, 2916, 3136, 3364, 3600, 3844, 4096, 4356, 4624, 4900, 5184, 5476, 5776, 6084, 6400, 6724, 7056, 7396, 7744, 8100, 8464, 8836, 9216, 9604, 10000]
A better way would be using the take() function, since it won’t bring the whole dataset into memory
even_rdd.take(3)
[4, 16, 36]
Example of join#
# Create two RDDs with key-value pairs
rdd1 = sc.parallelize([(1, "apple"), (2, "banana"), (3, "cherry")])
rdd2 = sc.parallelize([(1, "red"), (2, "yellow"), (3, "red"), (4, "green")])
# Perform a join operation on the two RDDs
joined_rdd = rdd1.join(rdd2)
# Collect and print the results
print(joined_rdd.collect())
[(1, ('apple', 'red')), (2, ('banana', 'yellow')), (3, ('cherry', 'red'))]
RDD Actions#
Actions are operations that trigger the execution of transformations and return a result.
Examples include
collect(),count(),take(), andreduce().
Example: Using reduce()#
The reduce() function in PySpark is an action that aggregates the elements of an RDD using a specified binary operator. It takes a function that operates on two elements of the RDD and returns a single element.
# Use reduce to sum all elements
sum_result = rdd.reduce(lambda x, y: x + y)
# Print the result
print(sum_result)
5050
5 Reasons on When to use RDDs#
You want low-level transformation and actions and control on your dataset;
Your data is unstructured, such as media streams or streams of text;
You want to manipulate your data with functional programming constructs than domain specific expressions;
You don’t care about imposing a schema, such as columnar format while processing or accessing data attributes by name or column; and
You can forgo some optimization and performance benefits available with DataFrames and Datasets for structured and semi-structured data.
References